
МАШИННОЕ ОБУЧЕНИЕ И АНАЛИЗ ДАННЫХ
Top 10 алгоритмов машинного обучения для новичков
Разбор популярных алгоритмов машинного обучения, которые активно используются сегодня и могут стать основой для вашего собственного алгоритма
Они могли бы стать похожими на учеников, которые многому научились у своего учителя, но добавили гораздо больше своего. Я думаю, что, когда это произойдет, придется признать, что машина демонстрирует наличие интеллекта
Один из примеров использования машинного обучения: программа миллиардного хедж-фонда "Man group's AHL Dimension" частично управляется искусственным интеллектом. После запуска ИИ в работу в 2016 году алгоритмы машинного обучения дали больше половины прибыли фонда, несмотря на то, что они управляли небольшой частью активов.
В статье мы рассмотрим 10 популярных алгоритмов машинного обучения, которые активно используются в торговом сообществе и могут стать основой для вашего собственного алгоритма.
В статье мы рассмотрим 10 популярных алгоритмов машинного обучения, которые активно используются в торговом сообществе и могут стать основой для вашего собственного алгоритма.
ЛИНЕЙНАЯ РЕГРЕССИЯ
Линейная регрессия изначально использовалась в статистике для исследования взаимосвязи между переменными, затем была адаптирована для прогнозирования на основе уравнений линейной регрессии.
В математике линейная регрессия — линейное уравнение, которое объединяет определенный набор входных данных (x) для прогнозирования выходного значения (y) на наборе входных значений. Линейное уравнение присваивает коэффициент каждому набору входных значений, которые называются коэффициентами, обозначаемыми греческой буквой Beta (β).
Уравнение ниже представляет модель линейной регрессии:
В математике линейная регрессия — линейное уравнение, которое объединяет определенный набор входных данных (x) для прогнозирования выходного значения (y) на наборе входных значений. Линейное уравнение присваивает коэффициент каждому набору входных значений, которые называются коэффициентами, обозначаемыми греческой буквой Beta (β).
Уравнение ниже представляет модель линейной регрессии:

, где
- два набора входных значений
- представляет выходные данные модели
- коэффициенты линейного уравнения
Когда есть только одна входная переменная, линейное уравнение описывает прямую линию на плоскости. Для простоты предположим, что β2 равен нулю, в этом случае переменная x2 не повлияет на выходные данные модели линейной регрессии. Тогда линейная регрессия будет представлять собой прямую линию на плоскости:
С помощью линейной регрессии можно выявить общий ценовой тренд акций за определенный период времени. Так можно понять, является ли изменение цены стабильно положительным или стабильно отрицательным.
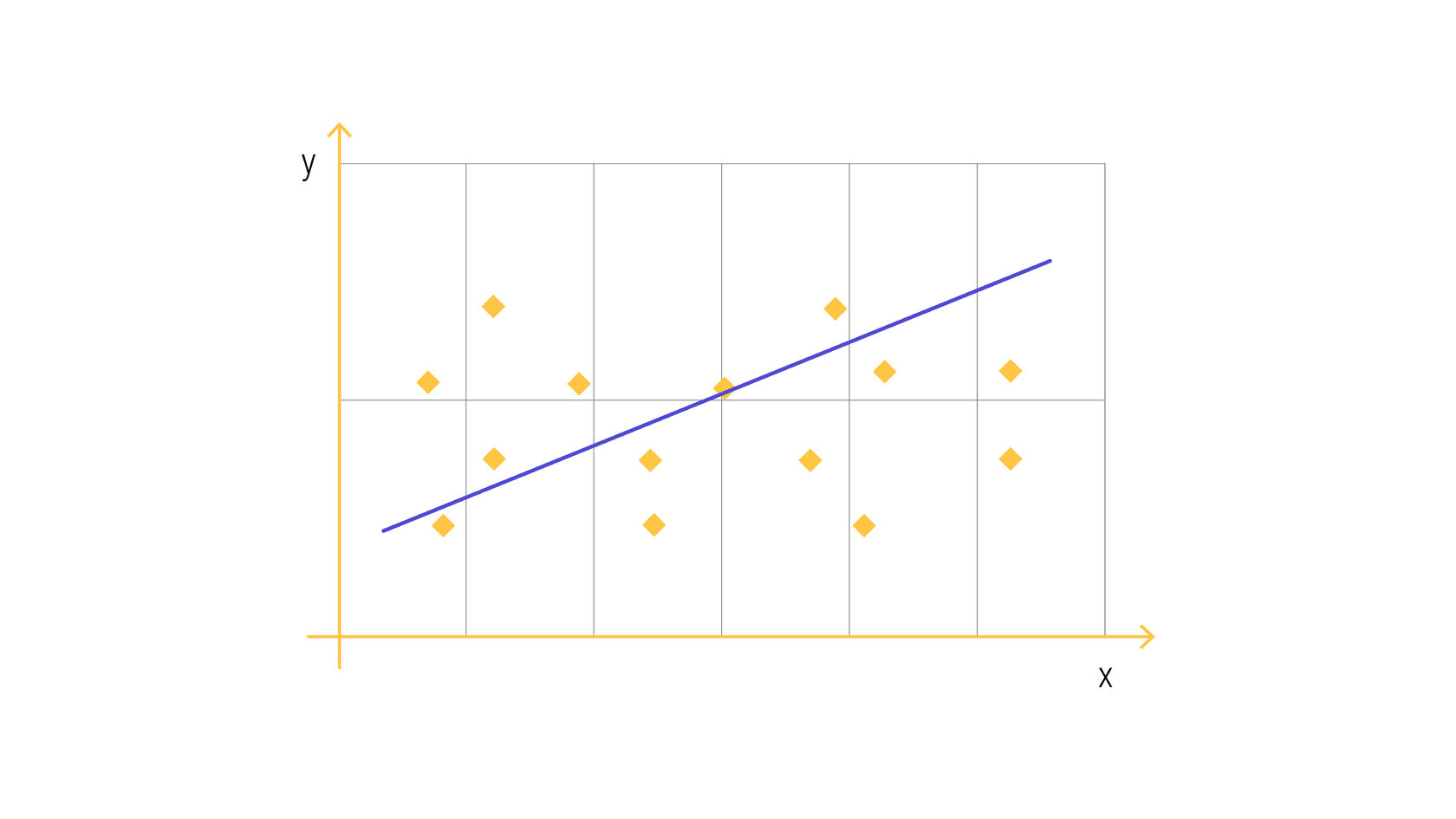
График модели уравнения линейной регрессии
ЛОГИСТИЧЕСКАЯ РЕГРЕССИЯ
Используя логистическую регрессию, мы получаем дискретное значения (1 или 0). Это соответствует ответу да-нет модели на текущие входные данные. В математике логистическая регрессия может быть представлена как:


Модель логистической регрессии вычисляет взвешенную сумму входных переменных, похожую на линейную регрессию, но она пропускает результат через специальную нелинейную функцию, логистическую функцию или сигмовидную функцию для получения ответа да-нет.
Сигмоидальная / логистическая функция задается следующим уравнением.
Сигмоидальная / логистическая функция задается следующим уравнением.
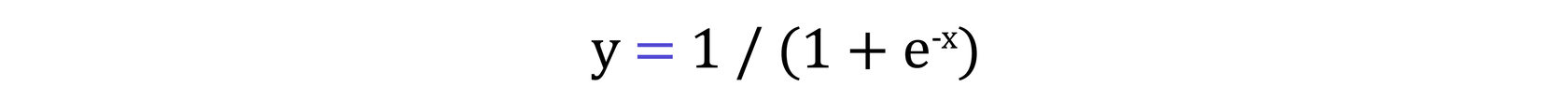
Проще говоря, логистическая регрессия может помочь прогнозировать направления рынка.

Сигмоида
МЕТОД k-БЛИЖАЙШИХ СОСЕДЕЙ
Цель метода k-ближайших соседей — классифицировать объекты на основе их сходства (например, функции расстояния).
Метод k-ближайших соседей учится в процессе: он не нуждается в предварительной фазе обучения и начинает классифицировать точки данных на основе большинства голосов их соседей.
Объект присваивается тому классу, за который голосует большинство ближайших соседей.
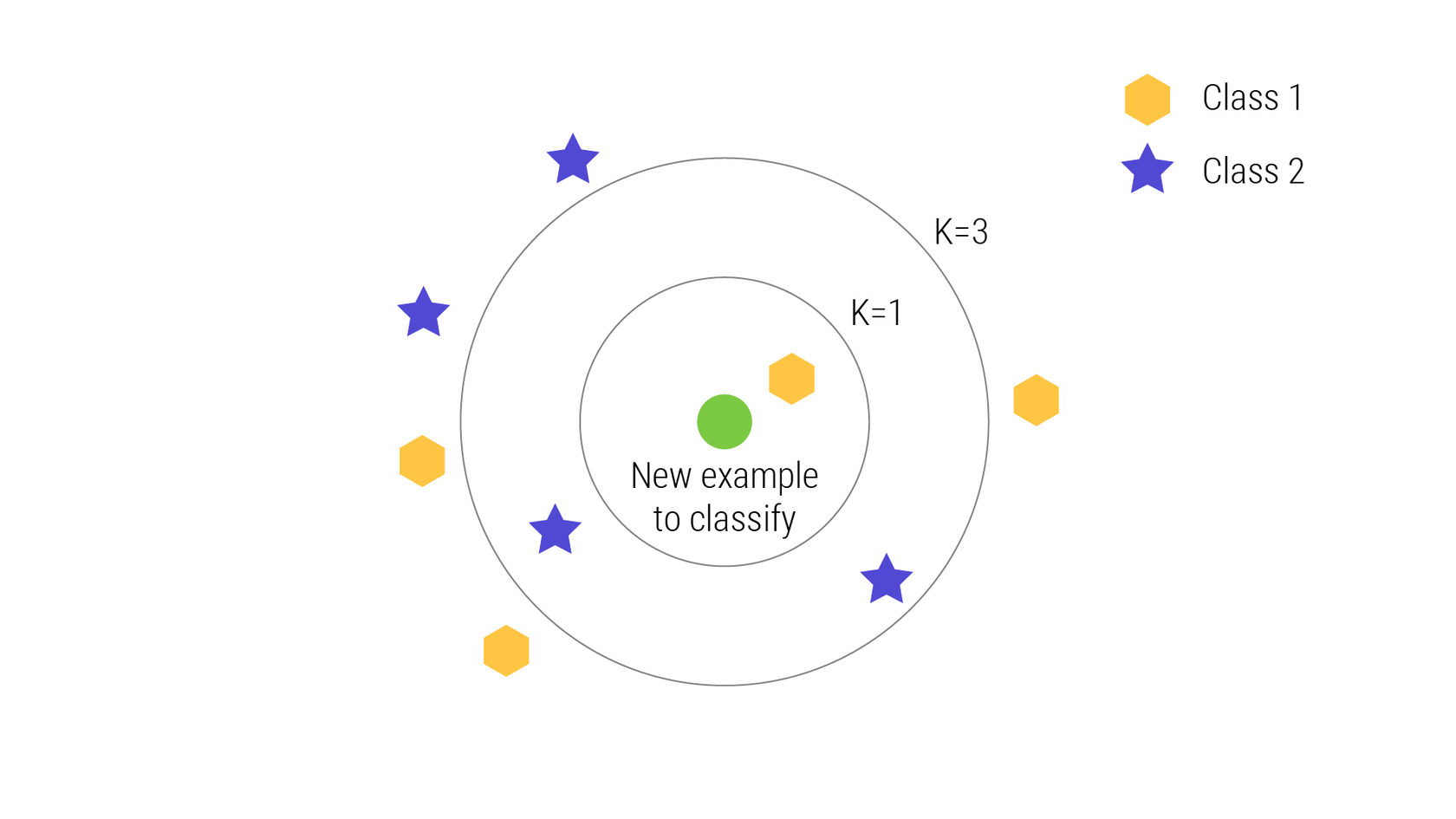
Давайте рассмотрим задачу присвоения зеленого круга классу 1 или классу 2. Рассмотрим частный случай метода k-ближайших соседей, когда k=1. В этом случае метод k-ближайших соседей присвоит зеленому кругу класс 1. Теперь давайте увеличим количество ближайших соседей до k=3, то есть 3 ближайших соседа. Как вы можете увидеть на рисунке: внутри круга находятся два объекта класса 2 и один объект класса 1. Метод k-ближайших соседей классифицирует зеленый круг как объект класса 2, поскольку они составляют большинство.
Метод k-ближайших соседей учится в процессе: он не нуждается в предварительной фазе обучения и начинает классифицировать точки данных на основе большинства голосов их соседей.
Объект присваивается тому классу, за который голосует большинство ближайших соседей.
Давайте рассмотрим задачу присвоения зеленого круга классу 1 или классу 2. Рассмотрим частный случай метода k-ближайших соседей, когда k=1. В этом случае метод k-ближайших соседей присвоит зеленому кругу класс 1. Теперь давайте увеличим количество ближайших соседей до k=3, то есть 3 ближайших соседа. Как вы можете увидеть на рисунке: внутри круга находятся два объекта класса 2 и один объект класса 1. Метод k-ближайших соседей классифицирует зеленый круг как объект класса 2, поскольку они составляют большинство.
МЕТОД ОПОРНЫХ ВЕКТОРОВ
Метод опорных векторов изначально использовался для анализа данных. Набор обучающих примеров подается алгоритму метода опорных векторов, а затем алгоритм строит модель, которая начинает присваивать новые данные одной из категорий, поданных на вход модели ранее.
Алгоритм метода опорных векторов создает гиперплоскость (это плоскость в пространстве размерности больше трех), которая отделяет классы. Когда алгоритм обрабатывает новую точку входных данных, она классифицируется в зависимости от того, с какой стороны находится от построенной моделью гиперплоскости.
Алгоритм метода опорных векторов создает гиперплоскость (это плоскость в пространстве размерности больше трех), которая отделяет классы. Когда алгоритм обрабатывает новую точку входных данных, она классифицируется в зависимости от того, с какой стороны находится от построенной моделью гиперплоскости.

ДЕРЕВЬЯ РЕШЕНИЙ
Деревья решений — это древовидный инструмент, который можно использовать для представления причины-следствия. Поскольку одна причина может иметь несколько следствий, мы перечисляем их ниже (как дерево с его ветвями).
Для торгов может быть построен алгоритм на основе метода опорных векторов, который получает данные по акциям с указанием благоприятных для покупки, для продажи или нейтральные, а затем классифицирует новые данные в соответствии с описанным алгоритмом.

Мы можем построить дерево решений, организовав входные данные и переменные этой модели-предсказателя в соответствии с некоторыми критериями.
Основные этапы построения дерева решений:
Недостаток деревьев решений: они склонны к переобучению из-за их структуры.
Основные этапы построения дерева решений:
- Получить рыночные данные для финансового инструмента
- Синтезировать входные данные (то есть технические индикаторы, индикаторы настроения, индикаторы ширины и так далее)
- Для всех входных данных установить целевые значения
- Разделить данные на тренировочные и тестовые
- Создать дерево решений для обучения модели
- Тестировать и анализировать модель
Недостаток деревьев решений: они склонны к переобучению из-за их структуры.
СЛУЧАЙНЫЙ ЛЕС
Алгоритм случайного леса позволяет обойти ограничения деревьев решений.
Случайный лес состоит из ансамбля деревьев решений, которые представляют собой графы решений с их действиями или статистической вероятностью. Предсказания деревьев проходят через одно итоговое дерево (CART).
Как работает классификация. Подсчитываются результаты предсказания всех деревьев ансамбля. Выбирается класс, который набрал наибольшее количество голосов.
Как работает регрессия. Результаты предсказаний всех деревьев усредняются. Это среднее и является результатом предсказания не отдельного дерева, а всей модели случайного леса.
Случайный лес состоит из ансамбля деревьев решений, которые представляют собой графы решений с их действиями или статистической вероятностью. Предсказания деревьев проходят через одно итоговое дерево (CART).
Как работает классификация. Подсчитываются результаты предсказания всех деревьев ансамбля. Выбирается класс, который набрал наибольшее количество голосов.
Как работает регрессия. Результаты предсказаний всех деревьев усредняются. Это среднее и является результатом предсказания не отдельного дерева, а всей модели случайного леса.
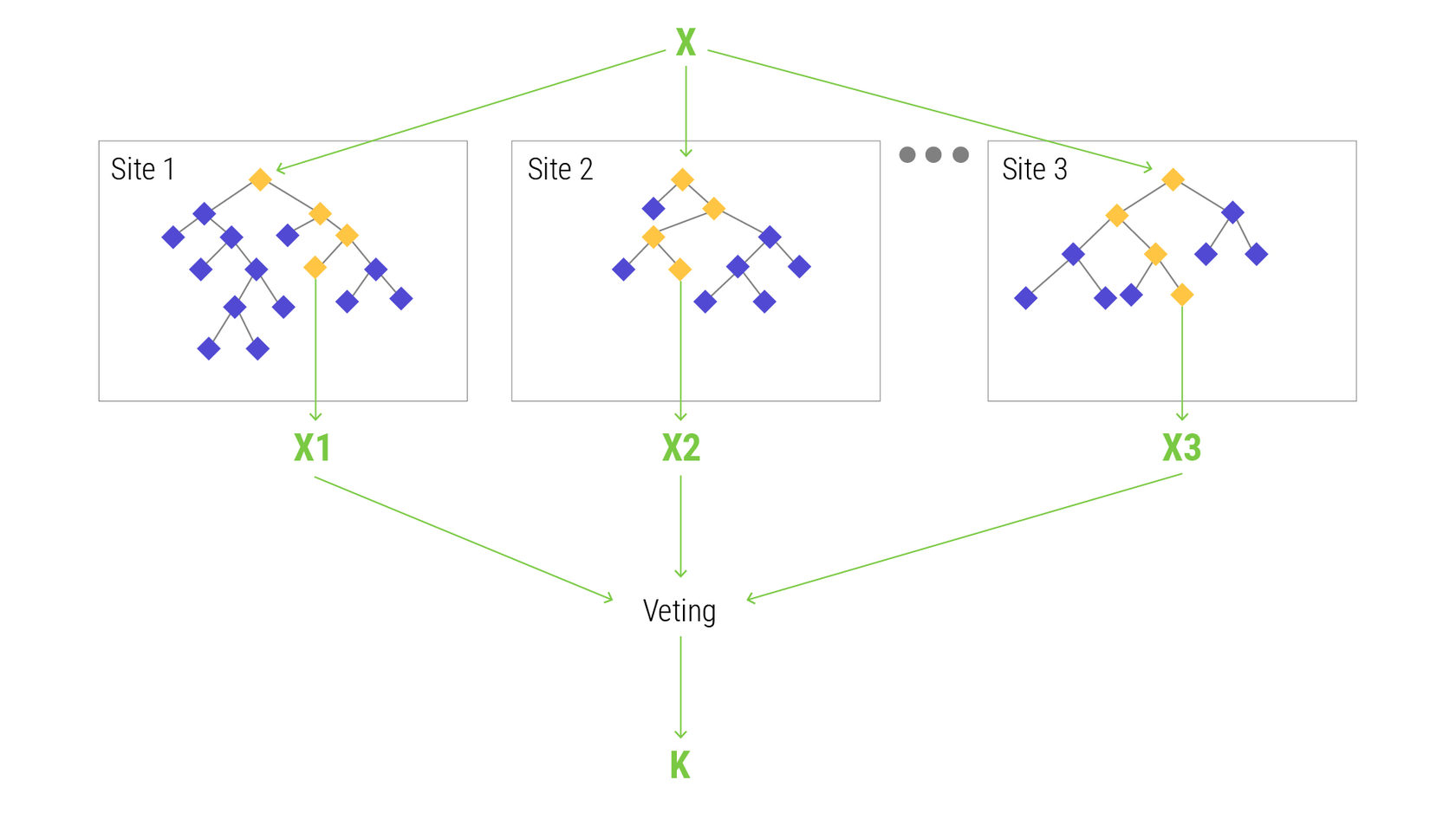
Как работает случайный лес:
- Предположим, что у нас есть N экземпляров тренировочных данных. Выборка из этих N экземпляров берется в качестве обучающего набора.
- Рассмотрим M как число входных признаков. Выбираем другое число m так, что m < M. Наилучшее разделение между m и M используется для разделения узла. Значение m не меняется по мере роста деревьев.
- Каждое дерево ансамбля растет по мере обучения.
- Объединяя прогнозы n деревьев (то есть большинство голосов за классификацию, среднее за регрессию), предсказываются новые данные.
ИСКУССТВЕННАЯ НЕЙРОННАЯ СЕТЬ
В нашей попытке играть в Бога искусственная нейронная сеть — одно из главных достижений. Мы создали несколько узлов, которые связаны между собой (как показано на рисунке) — именно так связаны нейроны в нашем мозге. Проще говоря, каждый нейрон получает информацию от другого, выполняет действие и передает его другому нейрону в качестве выходных данных.
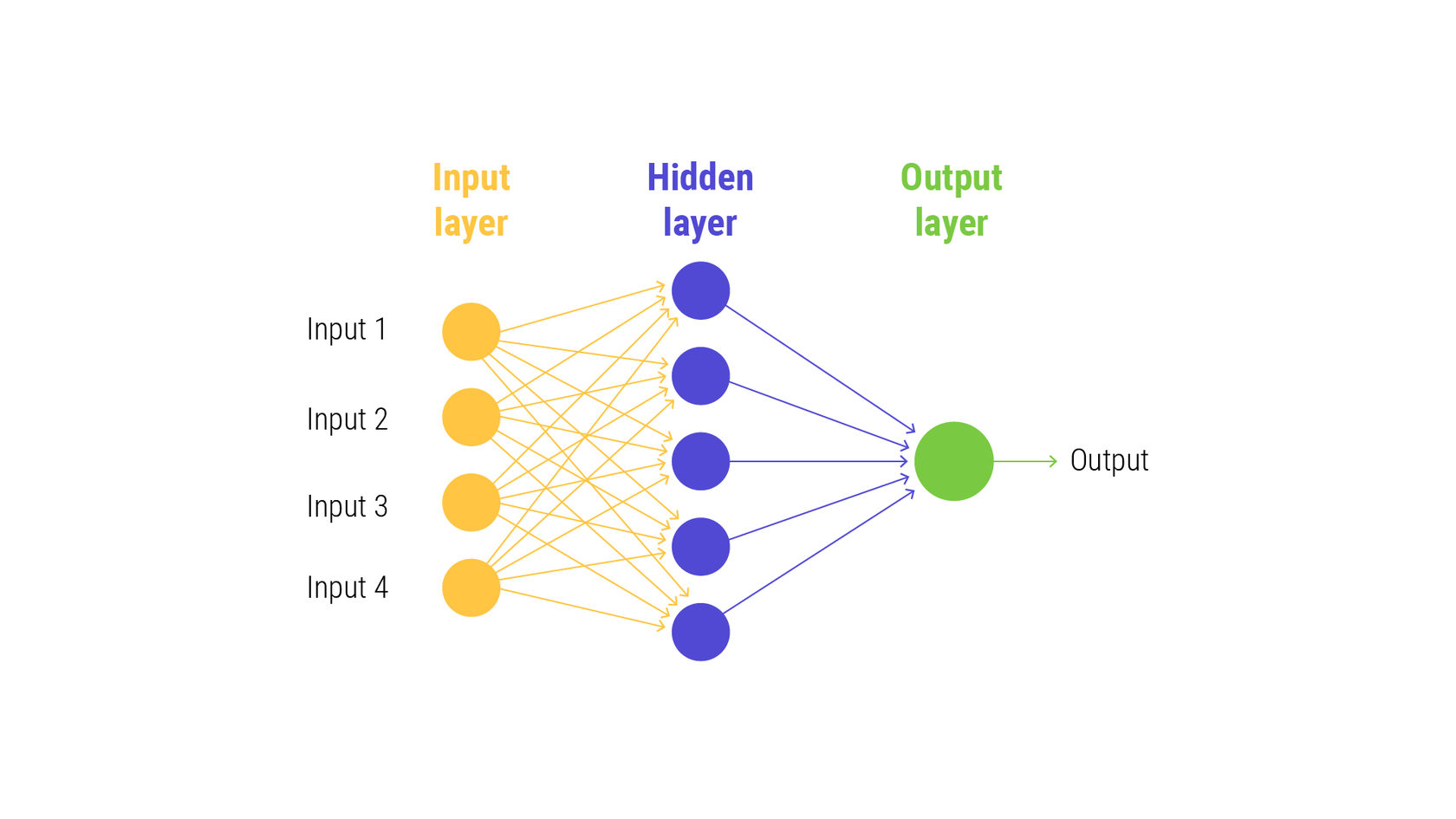
Один узел нейронной сети представляет из себя искусственный нейрон, а стрелка обозначает связь между выходом одного нейрона и входом другого.
Нейронные сети могут быть более полезными, если мы используем их для нахождения взаимозависимостей между различными классами активов, вместо того, чтобы пытаться предсказать выбор покупки или продажи.
Нейронные сети могут быть более полезными, если мы используем их для нахождения взаимозависимостей между различными классами активов, вместо того, чтобы пытаться предсказать выбор покупки или продажи.
МЕТОД k-СРЕДНЕГО
Цель этого алгоритма машинного обучения — маркировать точки данных в соответствии с их сходством. Мы не определяем кластеры до алгоритма, напротив, алгоритм находит эти кластеры по мере работы.
Простой пример: на основе данных о футболистах с помощью метода k-средних мы отметим их в соответствии с их сходством. Эти кластеры могут основываться на предпочтении нападающих забивать голы или обороняться, даже если алгоритму не даны предварительно определенные параметры для начала.
Кластеризация k-средних будет полезна для трейдеров, которые подозревают, что между различными активами есть неочевидные общие черты.
Простой пример: на основе данных о футболистах с помощью метода k-средних мы отметим их в соответствии с их сходством. Эти кластеры могут основываться на предпочтении нападающих забивать голы или обороняться, даже если алгоритму не даны предварительно определенные параметры для начала.
Кластеризация k-средних будет полезна для трейдеров, которые подозревают, что между различными активами есть неочевидные общие черты.

РЕКУРЕНТНЫЕ НЕЙРОННЫЕ СЕТИ
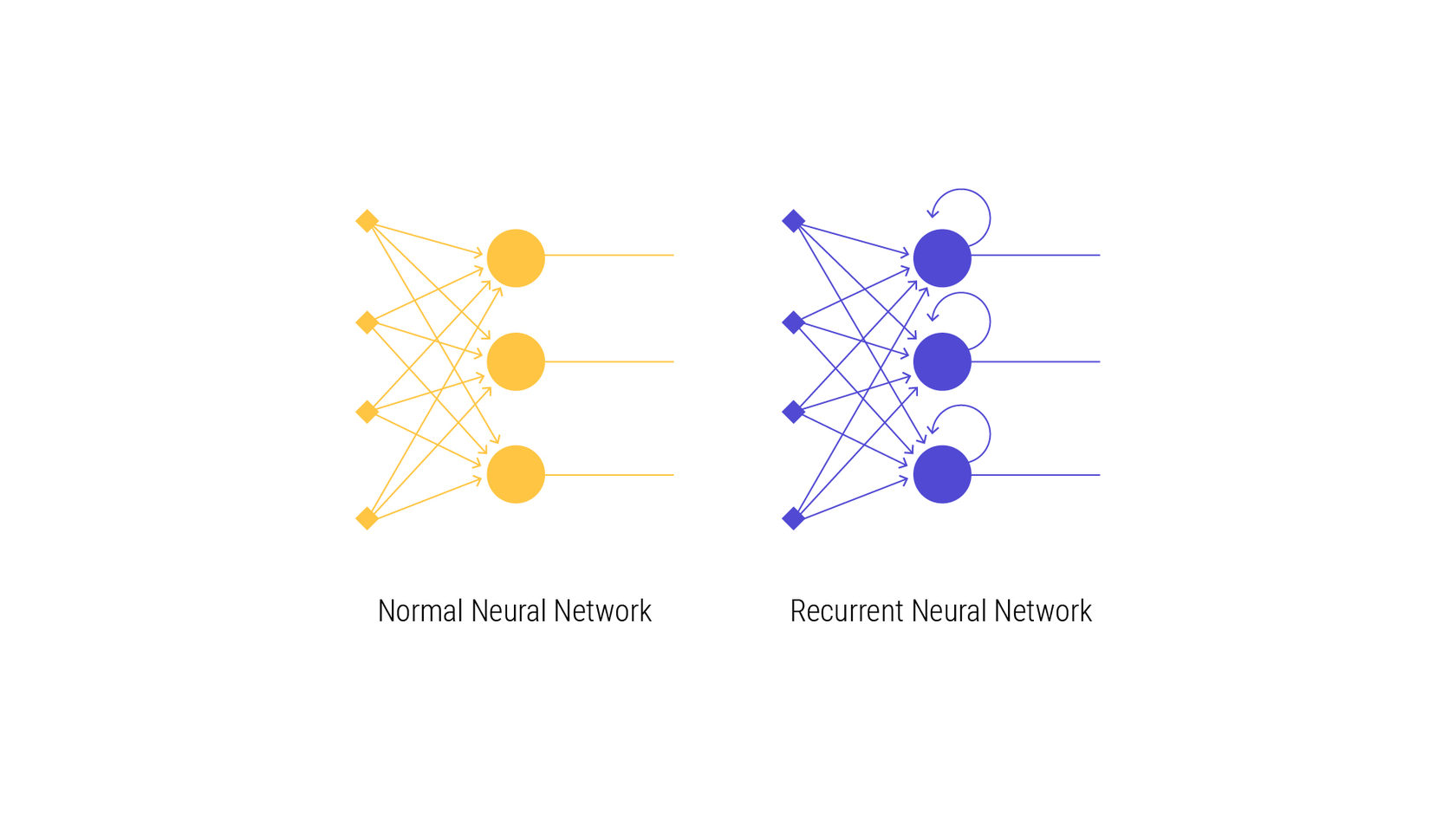
Знаете, что Siri и Google Assistant используют рекуррентные нейронные сети? Этот алгоритм — тип нейронной сети, в которой к каждому узлу прикреплена память, что упрощает обработку последовательных данных, то есть выходные данные зависят не только от текущих входных данных, но и от входных данных, которые уже были обработаны ранее.
Преимущество рекуррентной нейронной сети над обычной состоит в том, что нам нужно обрабатывать слово символ за символом. Возьмем слово «торговать»: узел нейронной сети забудет символ «т» к тому времени, когда он переместится на «г», тогда как рекуррентная нейронная сеть запомнит этот символ, поскольку у него есть собственная память.
Преимущество рекуррентной нейронной сети над обычной состоит в том, что нам нужно обрабатывать слово символ за символом. Возьмем слово «торговать»: узел нейронной сети забудет символ «т» к тому времени, когда он переместится на «г», тогда как рекуррентная нейронная сеть запомнит этот символ, поскольку у него есть собственная память.
НАИВНЫЙ БАЙЕСОВСКИЙ АЛГОРИТМ
Теорема Байеса была сформулирована таким образом, что у нас есть предварительные знания о любых событиях, связанных с предыдущими событиями.
Например, чтобы проверить вероятность опоздания на работу, необходим узнать, есть ли на вашем пути пробки.
Однако наивный байесовский алгоритм предполагает, что два события не зависят друг от друга, что в значительной степени упрощает вычисления. Этот алгоритм был изначально задуман исключительно для упражнений, но со временем стал использоваться и для реальных задач.
Наивный байесовский алгоритм можно использовать для поиска простых взаимосвязей между различными признаками объектов, когда данных мало.
Например, чтобы проверить вероятность опоздания на работу, необходим узнать, есть ли на вашем пути пробки.
Однако наивный байесовский алгоритм предполагает, что два события не зависят друг от друга, что в значительной степени упрощает вычисления. Этот алгоритм был изначально задуман исключительно для упражнений, но со временем стал использоваться и для реальных задач.
Наивный байесовский алгоритм можно использовать для поиска простых взаимосвязей между различными признаками объектов, когда данных мало.
ЗАКЛЮЧЕНИЕ
Согласно исследованию Preqin, 1360 количественных фондов используют компьютерные модели в процессе торгов, а это 9% всех фондов. Такие фирмы как Quantopian выдают денежные призы за стратегии машинного обучения людям, если им удается зарабатывать деньги на этапе тестирования, инвестируют свои собственные деньги и используют их в реальной торговле. Таким образом, быть на шаг впереди стремятся все: будь то хедж-фонды на миллиард долларов или индивидуальная предприниматели, — все пытаются понять и внедрить машинное обучение.
Вы можете пройти курс «Машинное обучение и анализ данных», разработанный совместно со специалистами Яндекс и МФТИ, чтобы подробно изучить эти алгоритмы, а также успешно и эффективно применять их на реальных рынках.
Вы можете пройти курс «Машинное обучение и анализ данных», разработанный совместно со специалистами Яндекс и МФТИ, чтобы подробно изучить эти алгоритмы, а также успешно и эффективно применять их на реальных рынках.
Статья подготовлена по материалам сайта https://www.quantinsti.com, программы "Машинное обучение и анализ данных" при участии специалиста по анализу данных Сергея Захарова
